FFI
Use the built-in bun:ffi module to efficiently call native libraries from JavaScript. It works with languages that support the C ABI (Zig, Rust, C/C++, C#, Nim, Kotlin, etc).
Usage (bun:ffi)
To print the version number of sqlite3:
import { dlopen, FFIType, suffix } from "bun:ffi";
// `suffix` is either "dylib", "so", or "dll" depending on the platform
// you don't have to use "suffix", it's just there for convenience
const path = `libsqlite3.${suffix}`;
const {
symbols: {
sqlite3_libversion, // the function to call
},
} = dlopen(
path, // a library name or file path
{
sqlite3_libversion: {
// no arguments, returns a string
args: [],
returns: FFIType.cstring,
},
},
);
console.log(`SQLite 3 version: ${sqlite3_libversion()}`);
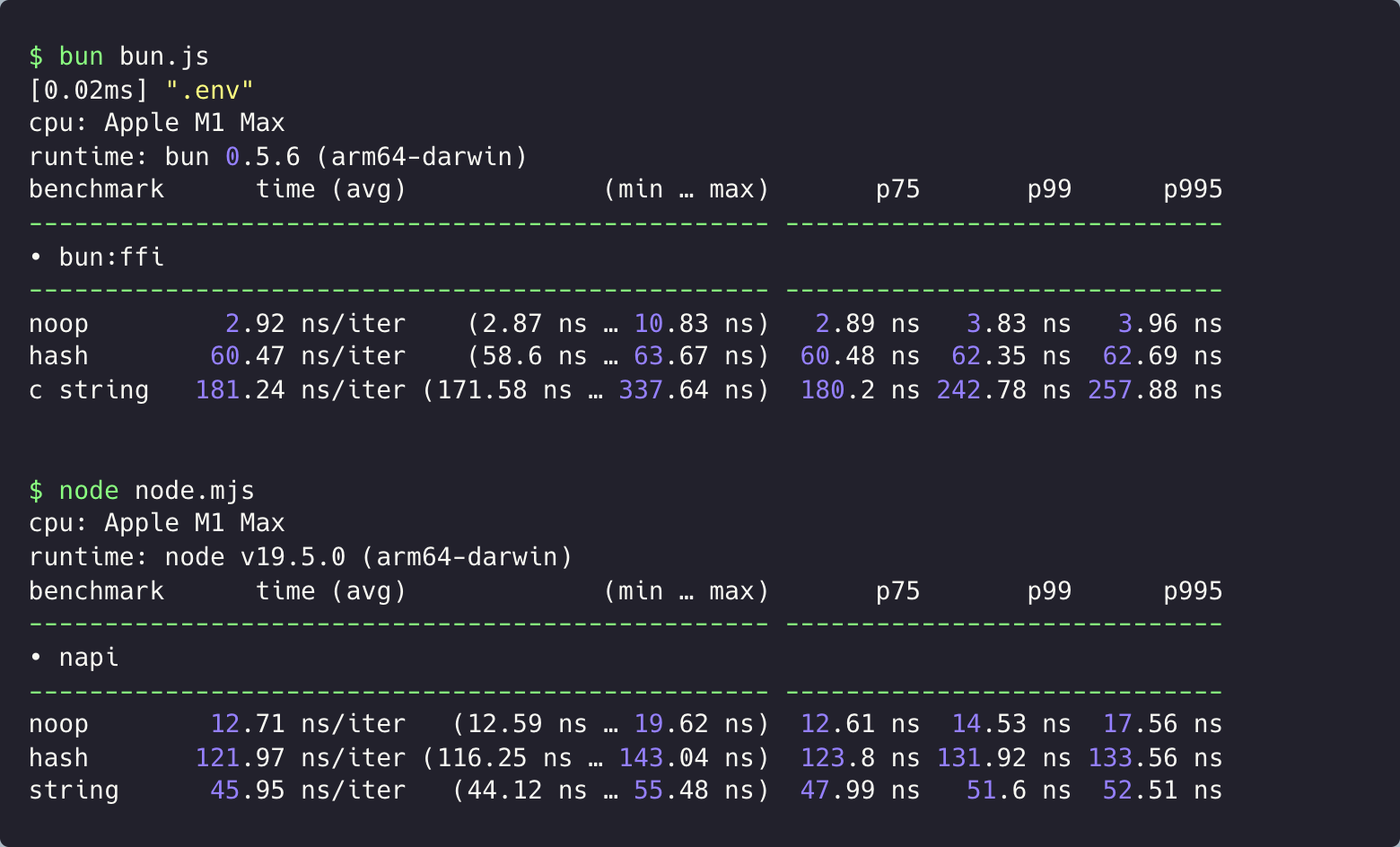
Performance
According to our benchmark, bun:ffi is roughly 2-6x faster than Node.js FFI via Node-API.
Bun generates & just-in-time compiles C bindings that efficiently convert values between JavaScript types and native types. To compile C, Bun embeds TinyCC, a small and fast C compiler.
Usage
Zig
// add.zig
pub export fn add(a: i32, b: i32) i32 {
return a + b;
}
To compile:
$ zig build-lib add.zig -dynamic -OReleaseFast
Pass a path to the shared library and a map of symbols to import into dlopen:
import { dlopen, FFIType, suffix } from "bun:ffi";
const { i32 } = FFIType;
const path = `libadd.${suffix}`;
const lib = dlopen(path, {
add: {
args: [i32, i32],
returns: i32,
},
});
console.log(lib.symbols.add(1, 2));
Rust
// add.rs
#[no_mangle]
pub extern "C" fn add(a: i32, b: i32) -> i32 {
a + b
}
To compile:
$ rustc --crate-type cdylib add.rs
C++
#include <cstdint>
extern "C" int32_t add(int32_t a, int32_t b) {
return a + b;
}
To compile:
$ zig build-lib add.cpp -dynamic -lc -lc++
FFI types
The following FFIType values are supported.
FFIType | C Type | Aliases |
|---|---|---|
| cstring | char* | |
| function | (void*)(*)() | fn, callback |
| ptr | void* | pointer, void*, char* |
| i8 | int8_t | int8_t |
| i16 | int16_t | int16_t |
| i32 | int32_t | int32_t, int |
| i64 | int64_t | int64_t |
| i64_fast | int64_t | |
| u8 | uint8_t | uint8_t |
| u16 | uint16_t | uint16_t |
| u32 | uint32_t | uint32_t |
| u64 | uint64_t | uint64_t |
| u64_fast | uint64_t | |
| f32 | float | float |
| f64 | double | double |
| bool | bool | |
| char | char |
Strings
JavaScript strings and C-like strings are different, and that complicates using strings with native libraries.
How are JavaScript strings and C strings different?
JavaScript strings:
- UTF16 (2 bytes per letter) or potentially latin1, depending on the JavaScript engine & what characters are used
lengthstored separately- Immutable
C strings:
- UTF8 (1 byte per letter), usually
- The length is not stored. Instead, the string is null-terminated which means the length is the index of the first
\0it finds - Mutable
To solve this, bun:ffi exports CString which extends JavaScript's built-in String to support null-terminated strings and add a few extras:
class CString extends String {
/**
* Given a `ptr`, this will automatically search for the closing `\0` character and transcode from UTF-8 to UTF-16 if necessary.
*/
constructor(ptr: number, byteOffset?: number, byteLength?: number): string;
/**
* The ptr to the C string
*
* This `CString` instance is a clone of the string, so it
* is safe to continue using this instance after the `ptr` has been
* freed.
*/
ptr: number;
byteOffset?: number;
byteLength?: number;
}
To convert from a null-terminated string pointer to a JavaScript string:
const myString = new CString(ptr);
To convert from a pointer with a known length to a JavaScript string:
const myString = new CString(ptr, 0, byteLength);
The new CString() constructor clones the C string, so it is safe to continue using myString after ptr has been freed.
my_library_free(myString.ptr);
// this is safe because myString is a clone
console.log(myString);
When used in returns, FFIType.cstring coerces the pointer to a JavaScript string. When used in args, FFIType.cstring is identical to ptr.
Function pointers
Note — Async functions are not yet supported.
To call a function pointer from JavaScript, use CFunction. This is useful if using Node-API (napi) with Bun, and you've already loaded some symbols.
import { CFunction } from "bun:ffi";
let myNativeLibraryGetVersion = /* somehow, you got this pointer */
const getVersion = new CFunction({
returns: "cstring",
args: [],
ptr: myNativeLibraryGetVersion,
});
getVersion();
If you have multiple function pointers, you can define them all at once with linkSymbols:
import { linkSymbols } from "bun:ffi";
// getVersionPtrs defined elsewhere
const [majorPtr, minorPtr, patchPtr] = getVersionPtrs();
const lib = linkSymbols({
// Unlike with dlopen(), the names here can be whatever you want
getMajor: {
returns: "cstring",
args: [],
// Since this doesn't use dlsym(), you have to provide a valid ptr
// That ptr could be a number or a bigint
// An invalid pointer will crash your program.
ptr: majorPtr,
},
getMinor: {
returns: "cstring",
args: [],
ptr: minorPtr,
},
getPatch: {
returns: "cstring",
args: [],
ptr: patchPtr,
},
});
const [major, minor, patch] = [
lib.symbols.getMajor(),
lib.symbols.getMinor(),
lib.symbols.getPatch(),
];
Callbacks
Use JSCallback to create JavaScript callback functions that can be passed to C/FFI functions. The C/FFI function can call into the JavaScript/TypeScript code. This is useful for asynchronous code or whenever you want to call into JavaScript code from C.
import { dlopen, JSCallback, ptr, CString } from "bun:ffi";
const {
symbols: { search },
close,
} = dlopen("libmylib", {
search: {
returns: "usize",
args: ["cstring", "callback"],
},
});
const searchIterator = new JSCallback(
(ptr, length) => /hello/.test(new CString(ptr, length)),
{
returns: "bool",
args: ["ptr", "usize"],
},
);
const str = Buffer.from("wwutwutwutwutwutwutwutwutwutwutut\0", "utf8");
if (search(ptr(str), searchIterator)) {
// found a match!
}
// Sometime later:
setTimeout(() => {
searchIterator.close();
close();
}, 5000);
When you're done with a JSCallback, you should call close() to free the memory.
⚡️ Performance tip — For a slight performance boost, directly pass JSCallback.prototype.ptr instead of the JSCallback object:
const onResolve = new JSCallback(arg => arg === 42, {
returns: "bool",
args: ["i32"],
});
const setOnResolve = new CFunction({
returns: "bool",
args: ["function"],
ptr: myNativeLibrarySetOnResolve,
});
// This code runs slightly faster:
setOnResolve(onResolve.ptr);
// Compared to this:
setOnResolve(onResolve);
Pointers
Bun represents pointers as a number in JavaScript.
How does a 64 bit pointer fit in a JavaScript number?
64-bit processors support up to 52 bits of addressable space. JavaScript numbers support 53 bits of usable space, so that leaves us with about 11 bits of extra space.
Why not BigInt? BigInt is slower. JavaScript engines allocate a separate BigInt which means they can't fit into a regular JavaScript value. If you pass a BigInt to a function, it will be converted to a number
To convert from a TypedArray to a pointer:
import { ptr } from "bun:ffi";
let myTypedArray = new Uint8Array(32);
const myPtr = ptr(myTypedArray);
To convert from a pointer to an ArrayBuffer:
import { ptr, toArrayBuffer } from "bun:ffi";
let myTypedArray = new Uint8Array(32);
const myPtr = ptr(myTypedArray);
// toArrayBuffer accepts a `byteOffset` and `byteLength`
// if `byteLength` is not provided, it is assumed to be a null-terminated pointer
myTypedArray = new Uint8Array(toArrayBuffer(myPtr, 0, 32), 0, 32);
To read data from a pointer, you have two options. For long-lived pointers, use a DataView:
import { toArrayBuffer } from "bun:ffi";
let myDataView = new DataView(toArrayBuffer(myPtr, 0, 32));
console.log(
myDataView.getUint8(0, true),
myDataView.getUint8(1, true),
myDataView.getUint8(2, true),
myDataView.getUint8(3, true),
);
For short-lived pointers, use read:
import { read } from "bun:ffi";
console.log(
// ptr, byteOffset
read.u8(myPtr, 0),
read.u8(myPtr, 1),
read.u8(myPtr, 2),
read.u8(myPtr, 3),
);
The read function behaves similarly to DataView, but it's usually faster because it doesn't need to create a DataView or ArrayBuffer.
FFIType | read function |
|---|---|
| ptr | read.ptr |
| i8 | read.i8 |
| i16 | read.i16 |
| i32 | read.i32 |
| i64 | read.i64 |
| u8 | read.u8 |
| u16 | read.u16 |
| u32 | read.u32 |
| u64 | read.u64 |
| f32 | read.f32 |
| f64 | read.f64 |
Memory management
bun:ffi does not manage memory for you. You must free the memory when you're done with it.
From JavaScript
If you want to track when a TypedArray is no longer in use from JavaScript, you can use a FinalizationRegistry.
From C, Rust, Zig, etc
If you want to track when a TypedArray is no longer in use from C or FFI, you can pass a callback and an optional context pointer to toArrayBuffer or toBuffer. This function is called at some point later, once the garbage collector frees the underlying ArrayBuffer JavaScript object.
The expected signature is the same as in JavaScriptCore's C API:
typedef void (*JSTypedArrayBytesDeallocator)(void *bytes, void *deallocatorContext);
import { toArrayBuffer } from "bun:ffi";
// with a deallocatorContext:
toArrayBuffer(
bytes,
byteOffset,
byteLength,
// this is an optional pointer to a callback
deallocatorContext,
// this is a pointer to a function
jsTypedArrayBytesDeallocator,
);
// without a deallocatorContext:
toArrayBuffer(
bytes,
byteOffset,
byteLength,
// this is a pointer to a function
jsTypedArrayBytesDeallocator,
);
Memory safety
Using raw pointers outside of FFI is extremely not recommended. A future version of Bun may add a CLI flag to disable bun:ffi.
Pointer alignment
If an API expects a pointer sized to something other than char or u8, make sure the TypedArray is also that size. A u64* is not exactly the same as [8]u8* due to alignment.
Passing a pointer
Where FFI functions expect a pointer, pass a TypedArray of equivalent size:
import { dlopen, FFIType } from "bun:ffi";
const {
symbols: { encode_png },
} = dlopen(myLibraryPath, {
encode_png: {
// FFIType's can be specified as strings too
args: ["ptr", "u32", "u32"],
returns: FFIType.ptr,
},
});
const pixels = new Uint8ClampedArray(128 * 128 * 4);
pixels.fill(254);
pixels.subarray(0, 32 * 32 * 2).fill(0);
const out = encode_png(
// pixels will be passed as a pointer
pixels,
128,
128,
);
The auto-generated wrapper converts the pointer to a TypedArray.
Hardmode
If you don't want the automatic conversion or you want a pointer to a specific byte offset within the TypedArray, you can also directly get the pointer to the TypedArray:
import { dlopen, FFIType, ptr } from "bun:ffi";
const {
symbols: { encode_png },
} = dlopen(myLibraryPath, {
encode_png: {
// FFIType's can be specified as strings too
args: ["ptr", "u32", "u32"],
returns: FFIType.ptr,
},
});
const pixels = new Uint8ClampedArray(128 * 128 * 4);
pixels.fill(254);
// this returns a number! not a BigInt!
const myPtr = ptr(pixels);
const out = encode_png(
myPtr,
// dimensions:
128,
128,
);
Reading pointers
const out = encode_png(
// pixels will be passed as a pointer
pixels,
// dimensions:
128,
128,
);
// assuming it is 0-terminated, it can be read like this:
let png = new Uint8Array(toArrayBuffer(out));
// save it to disk:
await Bun.write("out.png", png);